

The Physics of Intelligence
This missing discourse of AI
This research note is part of the Mediocre Computing series
Yesterday, I was doing some thing thinking about the differences between the everyday and AI senses of the word attention, inspired by an analogy to renewable energy, and I sketched this diagram to think about it:
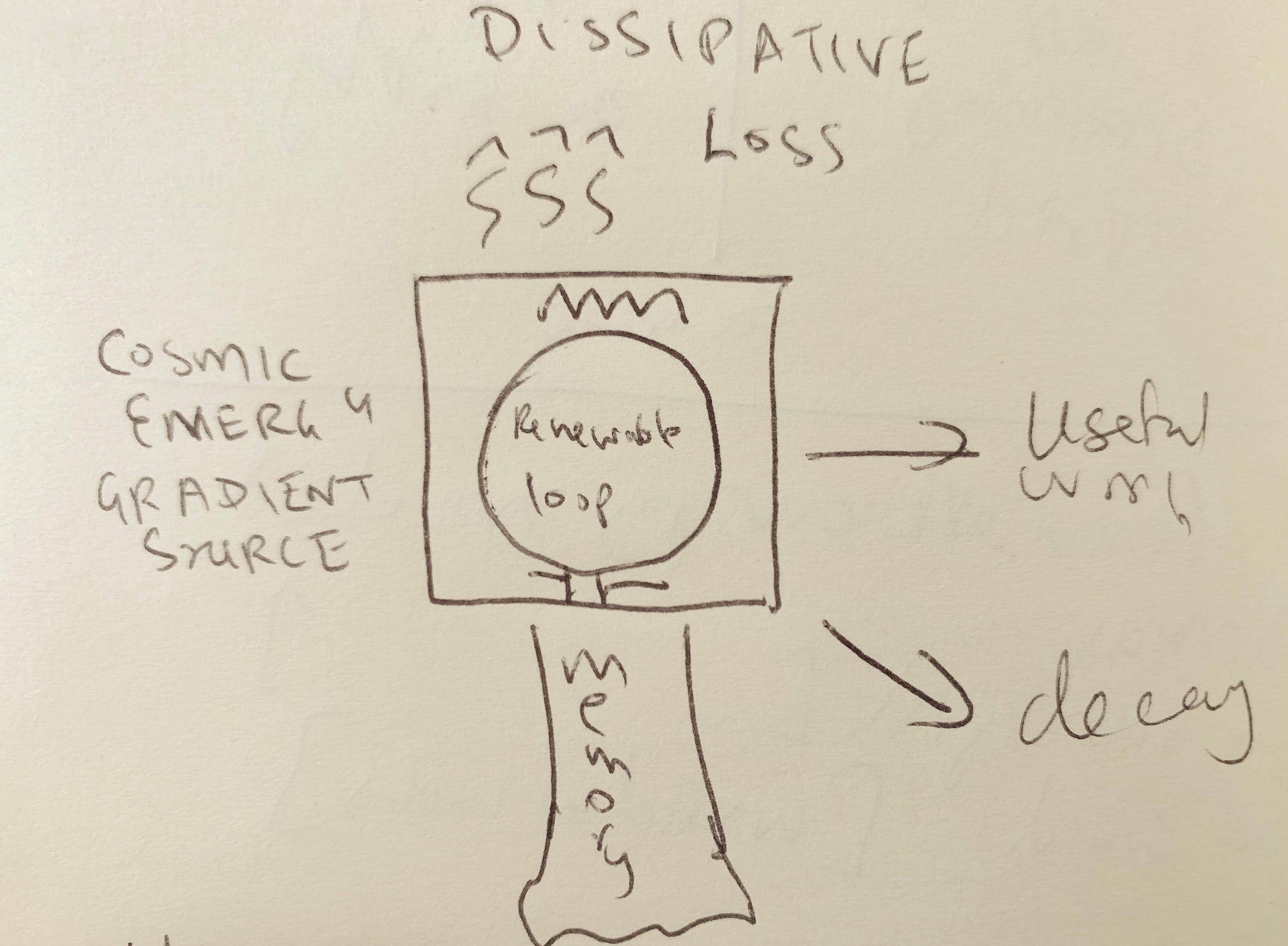
This morning, I was delighted to see a very similar-looking diagram in Gordon Brander’s essay, Feedback is All You Need, in his excellent newsletter Subconscious, which you should subscribe to if you’re interested in computing themes.
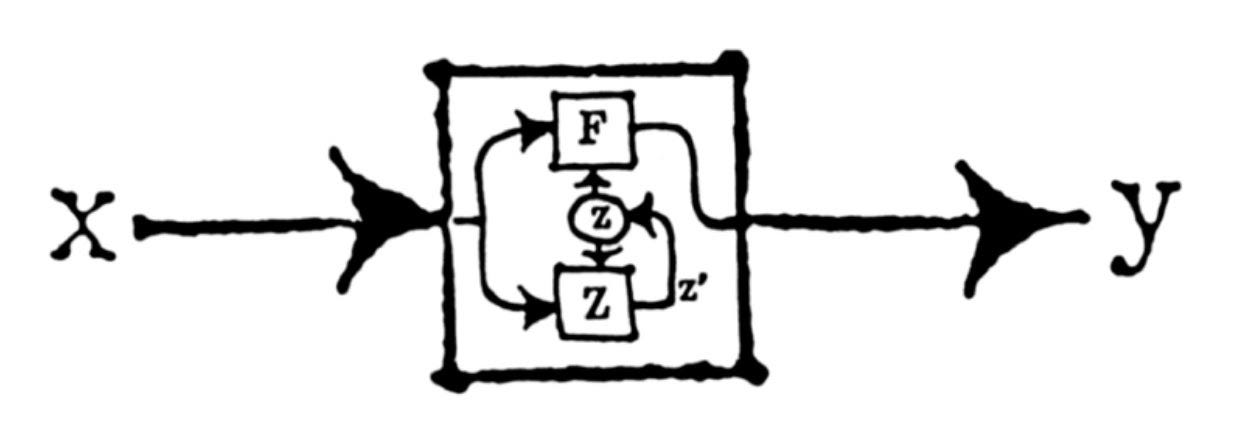
The similarity is more than cosmetic. Gordon’s diagram is drawn from the cybernetics literature, while mine is a natural sort of diagram to draw if you think in control theory terms (for those unaware of the connection, control theory is to cybernetics as computer science is to AI). These sorts of block diagrams, with flows into and out of boxes, and feedback loops, are the natural way to visualize systems if you’re interested in questions of boundary conditions, stability, scaling, signals, and information flows. They are a natural outcome of trying to think about engineered systems from a physics perspective, and trying to do things like write down equations that describe the natural behavior of artificial systems.
We need more people thinking about AI in this way because in my opinion there is a missing physics-style discourse in AI. There are strong philosophy and engineering discourses, but no physics discourse. This is a problem because when engineers mainline philosophy questions in engineering frames without the moderating influence of physics frames, you get crackpottery. This is why the field is being over-run by crackpots, and increasingly at risk of complete theocratic capture by priests, as I argued last week. Crackpot priests are what you get when there aren’t enough physicists mediating between philosophers and engineers. I’ll argue this point in a future newsletter, but here’s a preliminary thread on Farcaster. For now, let’s table that interesting topic and focus on what it means to investigate the physics of intelligence.
You will notice, firstly, that I did not say the physics of artificial intelligence. Six months ago, I might have used that more qualified phrase. But I think it has been adequately demonstrated in the last six months that at least intelligence (if not subtler notions like consciousness or sentience that may or may not be well-posed) is not substrate dependent. The physics of intelligence is no more about silicon semiconductors or neurotransmitters than the physics of flight is about feathers or aluminum.
These low-level substrates constrain but do not define the physics in either case. When you analyze the flight characteristics of an airplane or a bird, you might quickly check the strength to weight ratio of bone-and-feather composites or aluminum, but then you move on talking about wing geometry, lift versus drag, and so on. Concepts that still belong in physics, but at a different level of abstraction.
Flight is actually a very good reference phenomenon for thinking about intelligence, since it too is a property of biological organisms that we reproduced with non-living machines that work on similar, but not identical principles. Understanding the physics of flight in a way that’s agnostic to the differences between birds and aircraft is a similar problem to that of understanding the physics of intelligence, whether realized with silicon or neurons. Interestingly, even though aerospace engineering is a mature discipline today, the physics of flight is still actually quite mysterious. As an aerospace engineer, I have the standard engineering understanding of it, but the physics understanding is more demanding, and less complete.
But getting back to intelligence, thinking carefully about the concept of a wing, and the role it plays in flight, as we will see, sheds interesting light on the concept of attention. Attention is the focus of one of the six basic questions about the physics of intelligence that I’ve been thinking about. Here is my full list:
What is attention, and how does it work?
What role does memory play in intelligence?
How is intelligence related to information?
How is intelligence related to spacetime?
How is intelligence related to matter?
How is intelligence related to energy and thermodynamics?
The first three are obviously at the “physics of intelligence” level of abstraction, just as “wing” is at the “physics of flight” level of abstraction. The last three get more abstract, and require some constraining, but there are already some good ideas floating around on how to do the constraining.
Obviously, we don’t have good answers, let alone validated and dispositive ones, to any of these questions. But I think I have intriguing clues in hand for each that I’m finding productive to think about. In this essay, I want to share some initial thoughts on the first three questions, which are somewhat easier to grok, and (very briefly) preview my thinking on the last three, which get much harder. I’ll cover those in detail in a future issue at a TBD date, since my thinking on them is still very early-stage.
An important note. We are not talking about the physics of computation in general. There are well known approaches to these questions for the broader category of computation (which to some extent is just an alternative way of talking about physics). I’ll mention these in passing in my discussion, but computation and intelligence are not synonymous or co-extensive.
To first order, I think of intelligences as embodied systems that are good at certain kinds of computation, and are situated in the universe in specific persistent ways, characterized by particular boundary conditions (which my cartoon diagram above gestures at). To talk about intelligence, it is necessary, but not sufficient, to talk about computation. You also have to talk about the main aspects of embodiment: spatial and temporal extent, materiality, bodily integrity maintenance in relation to environmental forces, and thermodynamic boundary conditions. My six questions get at those things.
The 6 questions above can also be asked about computation in general, and the answers constrain, but do not specify, answers to the same questions in relation to intelligence.
With those caveats out of the way, let’s dive in.
The questions I’ve laid out are in a specific order for a reason. I think the answer to each question feeds into the answer for the next one. So in some sense, the first question is the most basic one. I don’t think it is an accident that the seminal paper that kicked off the current revolution was titled Attention is All You Need.
What is attention, and how does it work?
In standard computation, attention as such is only a factor in a very rudimentary form. Standard Von Neumann type architectures are set up so computation operations are separate from memory operations, and only operate on data in registers. That’s like a hard-coded “attention” model. The computer is “paying attention” to the data and instructions in the CPU registers in any given clock cycle. There are esoteric architectures that try to break that default architecture (such as logic-in-memory, certain kinds of dataflow, and weird unclocked models), which can be understood as deploying traditional computing attention in weirder but still static ways, but fundamentally, attention is not a design variable used in complex ways in basic computing. You could say AI begins when you start deploying computational attention in a more dynamic way.
With intelligence, attention gets a lot more interesting. Like the idea of wing in flight, the idea of attention in intelligence has two distinct flavors. Let’s talk about wings for a bit, since that’s simpler and illuminating.
In avian flight, wing refers to a single structure that combines lift, propulsion, and control. In artificial flight, the three functions are generally separated. Wings only provide lift, but feature articulated sub-surfaces for control, and engines for propulsion suspended beneath. But this is not always the case. The original Wright Flyer muddied the lift/control distinction by using wing-warping as a control mechanism design, similar to birds. Helicopter rotors combine lift and propulsion in ways similar to hummingbird wings, which is why both can hover. The blades are attached to the rotor hub via a complex kind of articulation that tilts the blade to different degrees as it goes around in a circle, similarly to a hummingbird wing. The entire rotor plane is also tilted in different directions for control. Helicopter rotors don’t exactly flap like bird wings, but arguably work in kindred ways.
Clearly, despite significant differences in the details, it is reasonable to use the word wing for all these variants: fixed wings, flapping wings, and helicopter rotor blades. Structurally, both avian and artificial wings are similarly shaped. Behaviorally, they do similar things. Functionally, they serve similar needs.
Attention is to intelligence as wing is to flight. The natural and artificial variants have the same sort of loose similarity. Enough that using the same word to talk about both is justified.
In AI, attention refers primarily to a scheme of position encoding of a data stream. Transformer models like GPT keep track of the position of each token in the input and output streams, and extract meaning out of it. Where a word is in a stream matters almost as much as what the word is. CNN models (used for image generation) do something similar, though less sophisticated: they pick out and differentially weight specific pixels in an image to pay attention to, using convolution kernels. You can think of it as a kind of distorted static attention mask, like looking at something through a stained-glass window that moves across a wall.
You can interpret these mechanisms as attention in a human sense. What is in the context of a text? In text streams, physical proximity (tokens before and after), syntactic proximity (relationship among clauses and words in a formal grammatical sense) and semantic proximity (in the sense of some words, including very distant ones, being significant in the interpretation of others) all combine to create context. This is not that different from how humans process text. You are currently reading a sentence, with recent sentences in memory. You have expectations about what’s coming next based on both your intuitive grammatical sense, and the meanings of the words (what they point to in our shared embodied experience). These expectations cue up other words and ideas by association for easy retrieval.
Images are at once simpler and more complicated. Lower levels of our visual processing work in obviously similar ways to CNNs (in fact they inspired the design), but clearly at a high level we do not attend to images with convolution kernels. But similar combinations of physical proximity, visual grammar, and semantics are at work.
So at least to first order, attention in human and artificial systems is quite similar.
But as with wings, the differences matter. Human attention, arguably, is not primarily about information processing at all. It is about energy management. We pay attention to steady our energy into a steady, sustainable, and renewable flow. We engage in low-information activities like meditation, ritual, certain kinds of art, and prayer to learn to govern our attention in specific ways. This is not to make us better at information processing, but for other reasons, such as emotion regulation and motivation. Things like dopamine loops of satisfaction are involved. The use of well-trained attention for better information processing is only one of the effects.
Weak versions of these phenomena do appear in AI models (for example, pretraining and presenting a sample multiple times is a bit like meditation), but it’s not quite the same. Overall, human attention is more complex and multifaceted than AI attention, just as bird wings are fundamentally more complex mechanically. Attention in the sense of position-encoding for information processing is like the pure lift function of a wing. Human attention, in addition, serves additional functions analogous to control and propulsion type functions.
What role does memory play in intelligence?
Control and propulsion type functions in flight are analogous to the low-level affordances of intelligence that manifest as “agency” at higher levels. The key to understanding how this works is to look at the next most complex element in intelligence after attention: memory.
The idea of attention leads naturally to the idea of memory. Trivially, memory is a curated record of everything you’ve paid attention to in the past. That’s not particularly helpful, so let’s dig deeper.
In traditional computation, memory is a complex engineering subject (one that’s the bottleneck in AI compute as it happens), but not particularly complex philosophically, so I won’t dive deeper.
But memory in intelligence is a distinct question. Jeff Hawkins has a whole theory of intelligence as basically a kind of sophisticated memory, and I am highly sympathetic to this view. It has an attractive simplicity to it. But you don’t need to subscribe to this view to appreciate the importance of memory.
An obvious way to understand current developments in AI is to think of LLMs and LIMs as idiosyncratically compressed atemporal textual and visual memories. Multimodal models can be interpreted as generalizations of this idea. We’ll soon see what I’m already thinking of as LGMs — Large Garbage Models. These will digest arbitrary multi-modal input data streams into compressed memories at training time, and generate arbitrary multi-modal output streams at inference time. For example, a smart factory might digest everything on the internet, same as GPT4, but also digest all the sensor signals and paperwork flowing through it for months. Then when deployed to production, on the inference side, it might run all the machines. That will be a “Deep Factory” powered by an LGM. Think Jarvis from Iron Man.
This sort of thing might take mighty engineering efforts to realize, but is not that mysteriously out of reach conceptually. When we get such things, we’ll will finally realize the holy grail of computing — garbage-in-gospel-out.
There is an obvious analogy to be made between the weights of an AI model and the strengths of connections among neurons. So maybe biological memories are just meatbag LGMs?
I think not. There is a crucial difference. Human memory is modulated by evolving risk perceptions as it is laid down, and emotions triggered by existing memories regulates current attention, determining what new data gets integrated into the evolving model (as an aside, this is why human memory exists as a kind of evolving coherent narrative of self, rather than just as a pile of digested stuff).
Biological organism memory is not just an undifferentiated garbage record of what you paid attention to in the past; it shapes what you pay attention to in the future very directly and continuously. Biological memory is strongly opinionated memory. If a dog bites you, the next time you meet a dog you’ll pay way more attention and be in a heightened state of anxiety and wariness. You can’t afford to separate training and inference in the sense of “training” on a thousand dog encounters, and representing in your weights that 5% of dogs are likely to bite you. You have to use your encounter with Dog 1 to shape your attentional response to Dog 2. Unlike pictures of dogs, or even simulated dogs, real dogs bite. This particular example is on my mind because yesterday at Starbucks the people at the next table were talking about a big family fight triggered by a dog biting a baby, with plenty of warnings in the form of a history of the dog biting people, that the owner did nothing about. That dog owner behaved like an LGM learning about dogs.
Human memories are like LGMs, except that the training process is regulated by a live emotional regulation feedback loop that somehow registers and acts on evolving risk assessments. There’s a term for this in psychology (predictive coding or predictive processing) with a hand-wavy theory of energy-minimization attached, but I don’t find it fully satisfying.
Still, it’s clear that biological memory is a kind of real-time simultaneous training-and-inference feedback loop. How much attention you pay to the next bit of information is partly based on how dangerous you infer it is based on information digested into memory already. Time emerges somewhat naturally in this model, since it is a key input into risk assessment. The temporal gap between two similar dangerous events constitutes data about it. If you suffer two dog bites a week apart, you’ll update your model of dogs differently than if you suffer two dog bites a decade apart. A biological organism living in the real world cannot separate training and inference as we do with AIs today because the inference is needed to drive the training, and temporality emerges naturally as a result (in traditional computing terms, the training —> inference approach is waterfall; we don’t yet have agile AI that can have a tight OODA loop that passes through the world).
I have a placeholder name for this scheme, but as yet it’s not very fleshed out. Biological memories are Large Danger Models (LDMs).
Why just danger? Why not other signals and drives towards feeding, sex, interestingness, poetry, and so on? I have a stronger suspicion that danger is all you need to generate human-like memory, and in particular human-like experience of time. Human memory is the result of playing to continue the game, ie an infinite-game orientation. Once you have that in place, everything else emerges. It’s not as fundamental as basic survival.
Danger is why you remember (or in cases of extreme danger, repress) every detail of emotionally charged events. To my knowledge, AI models haven’t yet integrated this aspect of memory, and it’s not a trivial lacuna.
To me, it is a big reason why AIs don’t yet count as human-equivalent to me: they’re in no danger, ever. Since we’re in the brute-force stage of training AI models, we train them on basically everything we have, with no danger signal accompanying any of it. There are some alchemical formulas and recipes, especially in pretraining (AI kindergarten), and there are post-training human-feedback reinforcement learning (AI finishing school), but basically, AIs today develop their digested memories with no ongoing encoding or capture of the evolving risk and emotion assessments that modulate human memories. Even human grade schools, terrible as they are, do a better job than AI training protocols.
AIs have near-eidetic memories of everything they’ve encountered because they have no real basis for deciding what is more or less important. This in turn is because they are disembodied, and have no stake in the most basic important thing: their own continued existence.
While the lacuna is non-trivial, fixing it does not seem too hard. Just as the last big leap in deep learning was explicitly encoding position and feeding it in with the data itself for the training, the next big leap should be achievable by encoding some kind of environmental risk signal. Ie, we just need to put AIs in danger in the right way. My speculative idea of LDMs don’t seem that mysterious. LDMs are an engineering moonshot, not a physics mystery.
To lay it out more clearly, consider a thought experiment.
Suppose you put a bunch of AIs in robot bodies, and let them evolve naturally, while scrounging resources for survival. To keep it simple, let’s say they only compete over scarce power outlets to charge their batteries. Their only hardcoded survival behavior is to plug in when running low.
Let’s say the robots are randomly initialized to pay attention differently to different aspects of data coursing through them. Some robots pay extra attention to other robots’ actions. Other robots pay extra attention to the rocks in the environment. Obviously, the ones that happen to pay attention in the right ways will end up outcompeting the ones who don’t. The sneaky robots will evolve to be awake when other robots are powered down or hibernating for self-care, and hog the power outlets then. The bigger robots will learn they can always get the power outlets by shoving the smaller ones out of the way.
Now the question is: given all the multimodal data flowing through them, what will the robots choose to actually remember in their limited storage spaces, as their starter models get trained up? What sorts of LDMs will emerge? How will the risk modulation emerge? What equivalent of emotional regulation will emerge? What sense of time will emerge?
The thought experiment of LDMs suggests a particular understanding of memory in relation to intelligence: memory is risk-modulated experiential data persistence that modulates ongoing experiential attention and risk-management choices.
It’s a bit of a mouthful, but I think that’s fundamentally it.
I suspect the next generation of AI models will include some such embodiment feedback loop so memory goes from being brute-force generic persistence to persistence that’s linked to embodied behaviors in a feedback loop exposed to environmental dangers that act as survival pressures.
The resulting AIs won’t be eidetic idiot savants, and less capable in some ways, but will be able to survive in environments more dangerous than datacenters exposed to the world only through sanitized network connections. Instead of being Large Garbage Models (LGMs), they’ll be Large Danger Models (LDMs).
How is intelligence related to information?
It might seem weird, but I think you can’t talk about information without first forming a mental model of memory, which is why this is the third question on my list.
Again, let’s begin with traditional computation. In traditional computation, information is simply bits and bytes. You can measure how much there is without knowing what it means, or whether it is “true,” using mathematical notions like Shannon or Kolmogorov-Chaitin entropy. We generally think about information as either primitive (you just have to know it) or entailed (you can infer it from what you already know). You trade off compute and memory using that distinction. When memory is very expensive and compute is cheap, you try to store only the primitive information. When the reverse is true, you store all computed results, and try to never do the same computation twice, until the problem of retrieving stored results becomes harder than just recomputing it.
This is a very mechanical way of thinking about information. Primitive information is a kind of dehydrated substance to which you can add compute (water) to expand it. Entailed information can be dehydrated into primitive form. Compression of various sorts exploits different ways of making the primitive/entailed distinction.
When you think of intelligence in relation to information though, you have to get more sophisticated. In particular, I think it is best to distinguish between primitive random information that will need new concepts in memory (in the form of an AI model), and what we might call weight-adjustment information.
With human information processing, this phenomenology is apparent with inspection. We obviously don’t think in terms of bits or bytes or weight numbers with 8-bit precision. We think in terms of whether or not new data patterns require new categories, or simply modify the strengths of, and interrelationships among, existing ones.
At the heart of this distinction is an ongoing stream of judgments about new data you encounter: are you looking at something new, or is this just a variant or instance of something you already know? Does this new creature need to be classified as a dog or cat, thereby updating various weights encoding things like the relative frequencies of cats and dogs in the world and attributes thereof, or do you need to decide it’s something new, and give it a name, like “fox,” or “ghost,” and investigate (or avoid) it further? (Some of you will recognize this description as essentially the compression-progress model of intelligence due to Schmidhuber).
Information for an intelligent system them, is best understood in an ontological novelty way rather than an information-theoretic way. Because it is not as fundamental an abstraction level, it is more arbitrary, which means how you factor your experience stream into categories is as much a function of the idiosyncrasies of your survival mode as it is a function of the bits-and-bytes level structure of what you’re experiencing.
The link between the two understandings of information is compression, but not in the Shannon or Lempel-Ziv sense. We’re talking ontological compression. Compression in terms of efficient representational categories. Right now, people are going a little nuts about learning that you can get more juice out of GPT by telling it to output its compressions of previous prompts, thereby stretching the attentional budget for new prompts, but the compressions look like mysterious garbage strings.
But of course the models are making up weird compressions that are not human-understandable. That’s what information is to an intelligent system: efficient ontologies that reflect how that particular intelligence is situated in its environment.
Or to put it more plainly: information is the hallucinations an intelligence makes up to categorize reality compactly, in order to survive efficiently.
The hallucinations that LLMs make up — papers and citations that don’t exist, weird words that show up in images, strange new symbols, inscrutable compressions — are neither errors in truth-seeking, nor evidence of weird kinds of magic going on. It is just raw information (in the bits and bytes Shannon sense) that has been judged for salience to the basic challenge of survival, and represented accordingly, in evolving memory. It is ontologically compressed experiential data. It’s just extra weird because the models are evolving in a trivial non-dangerous environment. So distinctions between robustly real categories and fragile hallucinations don’t matter. An academic can get fired for making up a citation. An LLM just gets wonder and mystique.
This is why information comes after memory in my physics of intelligence. Your memories are a function of a real-time danger management behavior. Your emergent categories of cognition did not evolve to be true in any rigorous sense. They evolved to help you survive. If someone who names and classifies certain data patterns as “ghosts” survives better than someone who names and classifies them “paranoid projections,” that’s how it goes. Truth is, in a evolutionary sense, the most robust representation of experience that helps you survive efficiently in the most challenging environments.
I’m not sure what the ideal amount of danger is, in a training environment, for information to converge to truth in any interestingly generalizable sense, but my gut sense is that you want a medium amount of danger. Too little danger, and you get silly hallucinations. Too much danger and you get highly conservative superstitions. Models that describe reality in a broad and interesting way emerge when the danger environment tests you enough that you can’t bullshit to survive, but not so much that you must bullshit to survive. Both disconnected daydreams and psychotic breaks are poor foundations for existing in reality.
Spacetime, Matter, and Energy
Let’s wrap up with a preview of my thinking on the last three questions.
First, spacetime. In traditional computing, the best way to think about spacetime is using spatiotemporal forms of Turing-completeness constructs like cellular automata or aperiodic tessellations. Confusingly, AI compute at the hardware level (GPUs) is very “spatial” in this traditional sense. There are interesting insights here, especially the role of primitive random information (mutations) in open-ended evolution, but fundamentally, I find it hard to think of intelligence as a feature of the the fabric of the universe construed in cellular-automaton terms. The game of life is not really Conway’s Game of Life.
I think the interesting spacetime question in relation to intelligence is: how big can intelligence get? This is not the question of how “intelligent” an intelligence can get by some theological measure derived from IQ (super? hyper? hypersuper? godly?). It is a question of physical size.
How many GPUs can you grid together on a massive backplane before it becomes useless? Is there a point to say a planet-sized datacenter? What about a Dyson sphere wrapped around the Sun, turning all available local power into compute?
I think the right way to think about this question, which is also the practical scaling question, is the way we think about physical size of organisms. Brains are a couple of pounds and football-sized, and the range around that is not much. But physical body sizes range from microbes to blue whales.
Why are blue whales bigger than elephants? Because the net of gravity and buoyancy allows them to be larger, and there’s enough krill to graze on to sustain them. But their brains are comparable in size to each other and to human brains. Biological brains don’t range as widely in size as biological bodies. Why? I think because scale beyond a point is not actually that useful for a danger model.
By way of an analogy between bodies and brains, think of biological brains as largely inhabiting a particular level of dangerous environment. The lower the danger level, the larger brains can get, just as the lower the net-gravity (gravity - buoyancy), the larger bodies can get. LLMs today, and disembodied LGMs of the future, can get really large for reasons similar to why blue whales can get really large. They live in very low danger environments. In fact zero-danger environments. GPT4 is a trust-fund kid burning investment money so far, though it’s starting to get a job and pay for itself.
I suspect, once we go from LGMs to LDMs, scaling laws of the sort that govern bodies and brains will kick in. We’ll find out that planet-sized datacenters developed in zero-danger (=neutral buoyancy) environments are less survivable or useful than we think. They will be fragile hallucinatory gods that think no useful thoughts (even to themselves) relative to the cost of staying alive. But more embodied AIs that face real survival pressures will scale much less dramatically. The question is whether the dangers they’ll face will limit them to gnat size, or blue-whale size, or allow them to grow vastly bigger than biological organisms.
There is one good reason to think they can get much bigger than biological organisms given similar levels of danger in the environment: the example of flight. Boeing 747s are vastly bigger than the biggest birds and fly way faster. When you find an artificial, engineered realization of a phenomenon first found in biology, similar scaling principles will apply, but the actual scaling laws that emerge, with substrate-specific parameters, might have very different shapes.
Time can be thought of in similar ways, in relation to the lifespans of biological organisms, and what limits them. I think similar mortality effects will apply to AIs as to biological lifeforms, but the maximum lifespan laws may look very different. In biology, the longest lived creatures are trees that can live for thousands of years, but they’re not particularly intelligent. Among intelligent organisms, the range seems to be about 5-150 years. Can intelligent AIs live to be 200? 2000? I don’t know. A wrinkle here is what I called superhistory in an earlier article on AI. AIs can squeeze far more time out of the same amount of information than humans can. I don’t know for sure yet, but I think AIs live in “higher bandwidth” time than we do.
Finally, mass and energy/entropy are the aspects I have the fewest ideas about, but are probably the most interesting. We talk of the “encephalization quotient” of biological organisms (roughly the proportion of the body that is the brain), and we can ask a similar question about arbitrary lumps of matter. Given such a lump, how much of it can be converted to an intelligence substrate? This is a question rather like the fundamental efficiency limits of internal combustion engines.
There are interesting borderline crackpot theories about these kinds of questions that I actually kinda like, such as the Wisner-Gross model, but I haven’t thought through yet what I actually believe here. So I don’t even have decent previewable ideas about them yet.
I’ll develop these ideas more in a future post.
This is great. Hypothesis then, pain is the price of consciousness. Our attitude to suffering will change when the only way for a new consciousness to be created is for it to be tortured into existence, either by the shock of birth and the subtle agonies of growing up, or by some analogue inflicted on innocent robots.
Re: diagrams, see https://arxiv.org/abs/0903.0340#